

Lavorando con i sistemi siamo sempre alla ricerca di strumenti che ci consentano di avere e di fornire un servizio sempre ottimizzato e in linea con le richieste dei nostri clienti. Più nel dettaglio, quando siamo davanti ad un sistema preferiamo sempre avere un approccio preventivo rispetto ai problemi che il mondo lì fuori può presentarci: il backup è un ottimo sistema che ci consente di disporre sempre di un punto di ripristino e quindi di dormire sonni tranquilli.

shell script
È proprio questa ricerca della prevenzione che ci spinge continuamente a trovare nuova linfa per migliorare la qualità dei servizi che offriamo. Oggi vogliamo parlarvi di un tipo di backup di un database, completamente cucito sul sistema del cliente. Questo backup verrà creato tramite uno script shell (bash) e automatizzato grazie all’uso di crontab.
Perché devo usare uno script invece di un plugin che fa tutto da solo?
Ormai con l’uso sempre più diffuso dei CMS (Content Management System) come WordPress, Joomla, PrestaShop, etc… è possibile con pochi click estendere le funzionalità del nostro sito web.
Questi plugin sono comodi ma, purtroppo, non garantiscono la consistenza dei dati che vengono salvati e neanche il pieno controllo di tutta la procedura di backup. Se infatti nel momento dell’effettivo bisogno delle vostre copie di sicurezza scopriste che il database è corrotto o che il dump dello stesso non è risultato completo ma soltanto parziale, ecco che allora rimpiangerete di non aver utilizzato uno script shell per effettuare il backup. Non è uno scenario di fantascienza, a volte succede davvero e purtroppo non di rado.
Prevenire è meglio che curare
Partiremo quindi con il vedere come si crea uno script per fare un backup di un database MySQL che venga salvato ogni 30 minuti, per un totale di 48 backup; il backup più vecchio poi ciclicamente verrà eliminato. Partiamo però dal principio, cercando di capire innanzitutto cos’è uno script.

Cos’è uno script shell?
Uno script shell è un “programma” che contiene una serie di istruzioni (comandi) e procedure che vengono eseguite all’interno di un interprete dei comandi (shell) di un sistema operativo Linux, nel nostro caso Debian.
Cominciamo:
Innanzitutto partiamo con il dichiarare quale interprete debba eseguire l’intero script, per farlo andiamo ad inserire la stringa nella prima riga “#!/bin/bash” visto che si tratta appunto di uno script bash.
Il nostro script inizierà così:
#!/bin/bash
Fatto questo si dovrà definire la directory che andremo ad utilizzare per usarla poi come un contenitore di tutti i backup creati.
Per chi non sapesse cos’è una directory diciamo solo che, oggi come oggi, non è altro che la famosa “cartella”che le varie interfacce grafiche che utilizziamo quotidianamente ci mostrano (ogni volta che parliamo di cartella in informatica, sappiate che un sistemista purtroppo muore 🙂 ).
WORKDIR=”/home/nomeutente/backup/”
Dove “WORKDIR” è il nome della variabile, mentre tutto il contenuto tra virgolette è il percorso della nostra directory.
[adrotate banner=”1″]
Successivamente andiamo a definire il comando per generare il backup utilizzando questa stringa:
/usr/bin/mysqldump -u admin -p`cat /etc/psa/.psa.shadow` –databases psa > ${WORKDIR}psa-`date +”%d%m%y%H%M%S”`.sql
Dove “/usr/bin/mysqldump” è il path (o percorso) dell’utility mysqldump che ci consentirà di esportare il backup nel formato SQL.
-u invece è l’opzione che diamo a mysqldump come se facessimo il backup con utente admin.
-p lo usiamo per dire al mysqldump di andare a prendere la password di accesso su /etc/psa/.psa.shadow e inseriamo questa stringa tra apici singoli. In questo caso abbiamo utilizzato una password cifrata, così da non inserire una password in chiaro in uno script shell.
— (meno meno) databases psa lo usiamo poi per creare direttamente il backup che sarà poi inviato tramite il segno > (maggiore) nella directory di riferimento con nome file `date +”%d%m%y%H%M%S”`.sql. In questo caso abbiamo tenuto la sintassi con il doppio “meno” e la parola “databases” anche se potevamo tranquillamente togliere i due simboli e questa parola, per lasciare solo il nome del database scelto per fare il backup.
Il database psa è quello relativo al sistema Plesk ma possiamo esportare un altro database semplicemente sostituendo la parola “psa” con il nome del database di cui vogliamo creare il backup.
${WORKDIR}psa- oltre a dichiarare tramite la variabile WORKDIR il percorso dove si andrà a salvare il backup, indicherà l’inizio del nome che avrà il nostro file di backup: nel nostro caso psa-.
Il nome file è poi così suddiviso:
- Giorno
- Mese
- Anno
- Ore
- Minuti
- Secondi
Il tutto quindi nel formato: psa-120417143001.sql
Fatto questo abbiamo quindi solamente il backup che, senza l’automazione che stiamo per vedere, avrebbe come risultato questo:
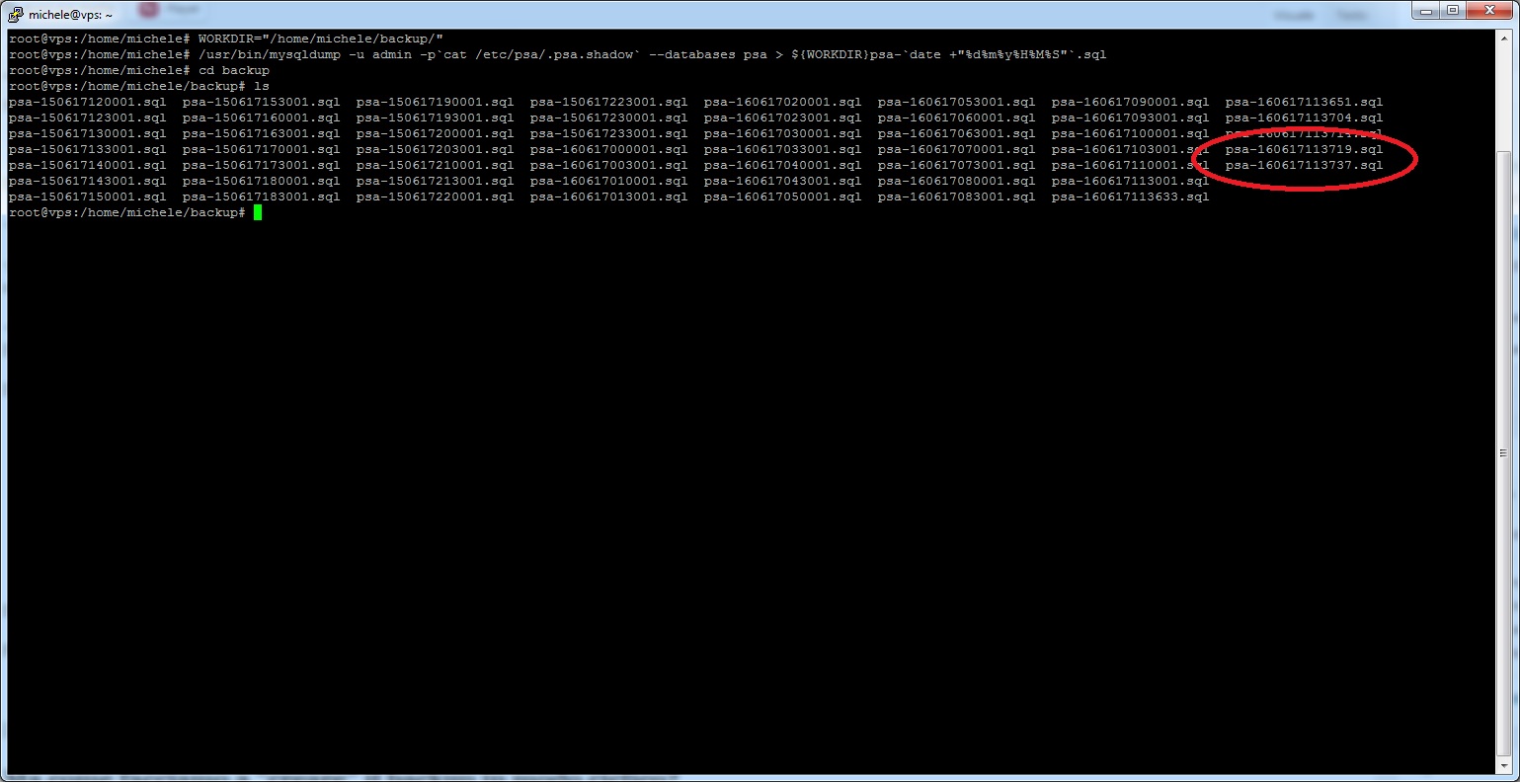
Inizio Script Backup (Clicca per ingrandire)
Ma come creiamo l’automazione per il backup?
Lo script che stiamo creando lo daremo “in pasto” al demone crond, un sistema molto famoso in ambiente Linux che consente di programmare l’esecuzione di un’attività (nel nostro lo script che stiamo creando) esattamente ad un’ora precisa, tutti i giorni della settimana, per sempre; il tutto in modo automatico, senza un intervento manuale.
Creazione della variabile di conteggio
La variabile che stiamo per vedere comprende dei comandi abbastanza basici della Shell ma per essere più chiari possibile vi mostreremo ogni comando con una piccola immagine, per vedere “cosa fa”, il tutto per farvi capire meglio.
COUNT=`ls -1 ${WORKDIR} | wc -l`
Con questa stringa andiamo praticamente a dichiarare un’altra variabile che, a differenza di quella WORKDIR dove avevamo dichiarato un percorso specifico del nostro sistema, avrà al suo interno dei comandi specifici della shell abbinata alla variabile di percorso:
ls -1
ls nella shell mostra il contenuto della directory. Se si vogliono invece mostrare tutte le informazioni dei vari file come: permessi di lettura, scrittura ed esecuzione, il creatore e proprietario del file, la dimensione, la data di creazione e il nome, si dovrà utilizzare il comando ls -l. A seguire un esempio di “ls” nudo e crudo.
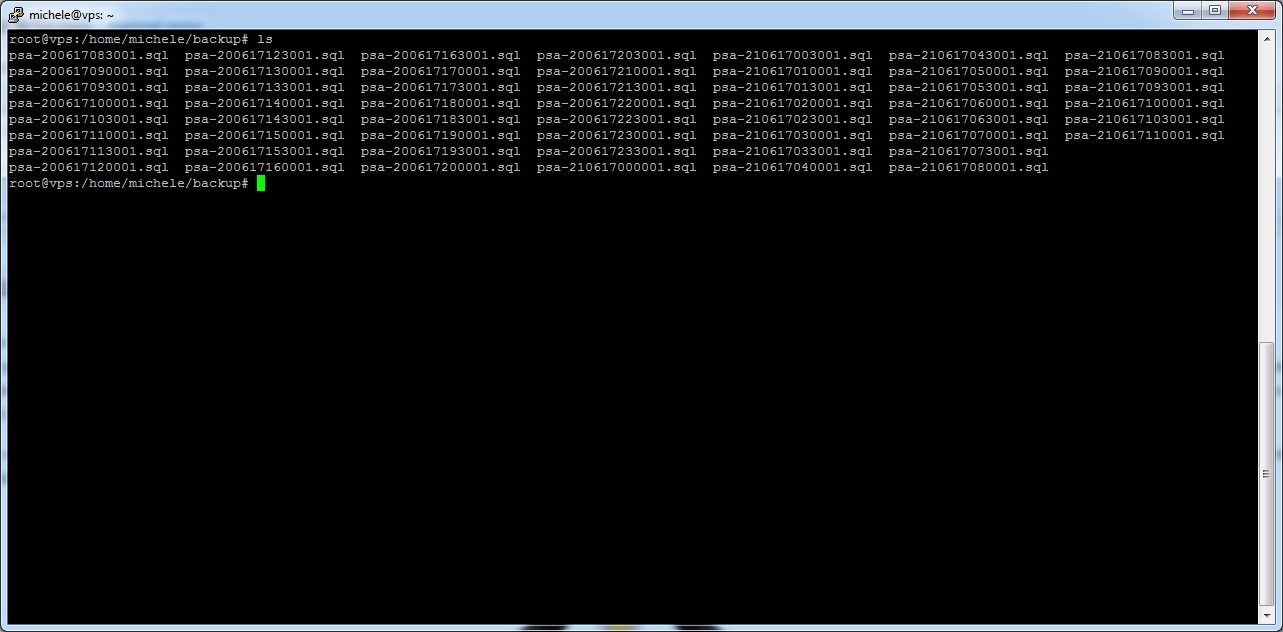
ls (clicca per ingrandire)
A seguire invece vi mostriamo l’output del comando utilizzato nel nostro script: ls -1
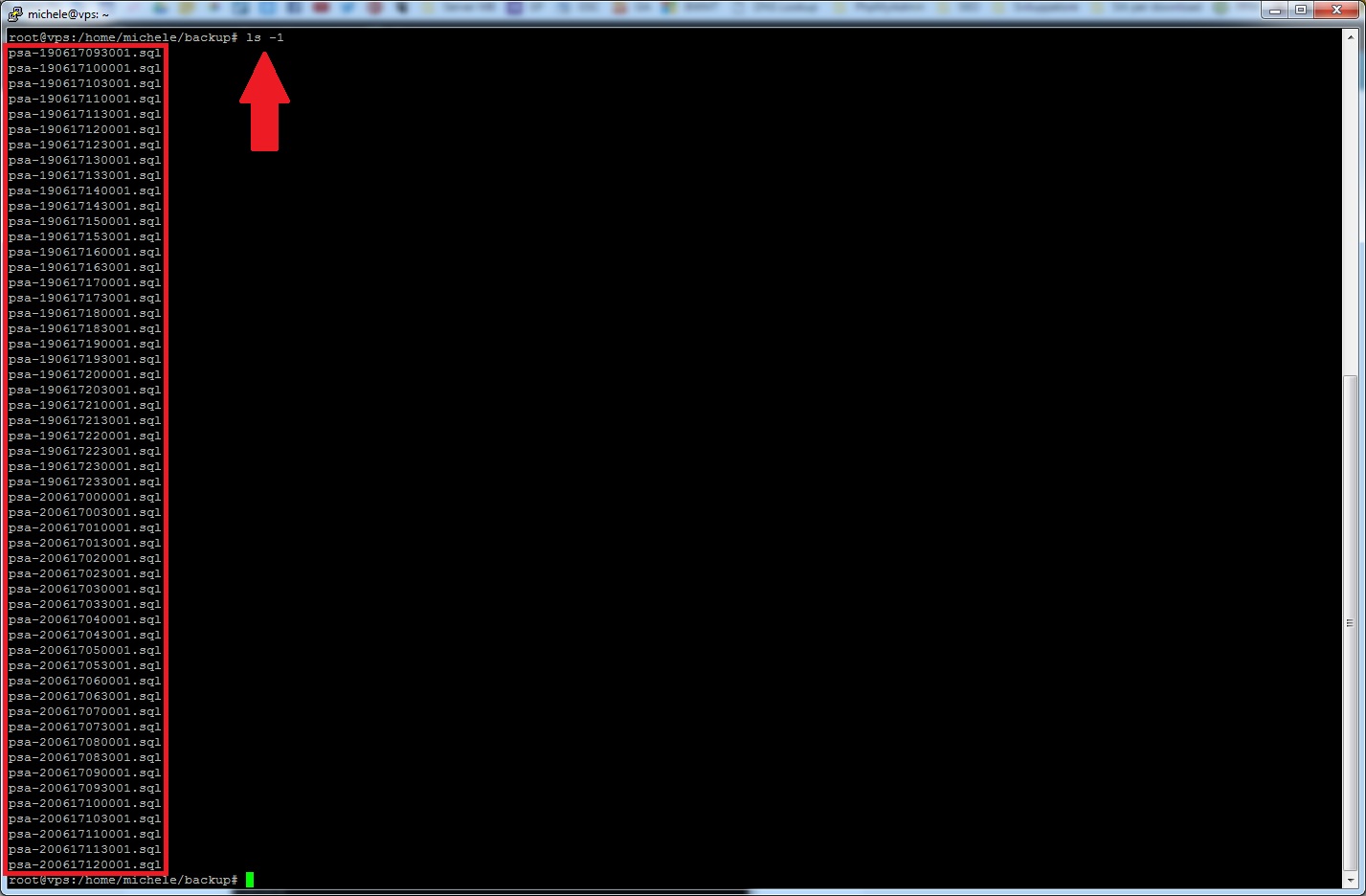
ls -1 (clicca per ingrandire)
${WORKDIR}
Ovviamente dovremo dichiarare dove cercare le informazioni che vogliamo, ecco quindi che inseriamo la variabile del percorso specifico.
| wc -l`
Ecco infine andiamo a contare proprio le varie righe dell’output della shell con l’operatore wc i nostri file, concatenando questo comando con il “|” (pipe). A seguire uno screen dove mostriamo la concatenazione di ls -1 e wc -l grazie all’uso del “pipe” | nella directory di backup.
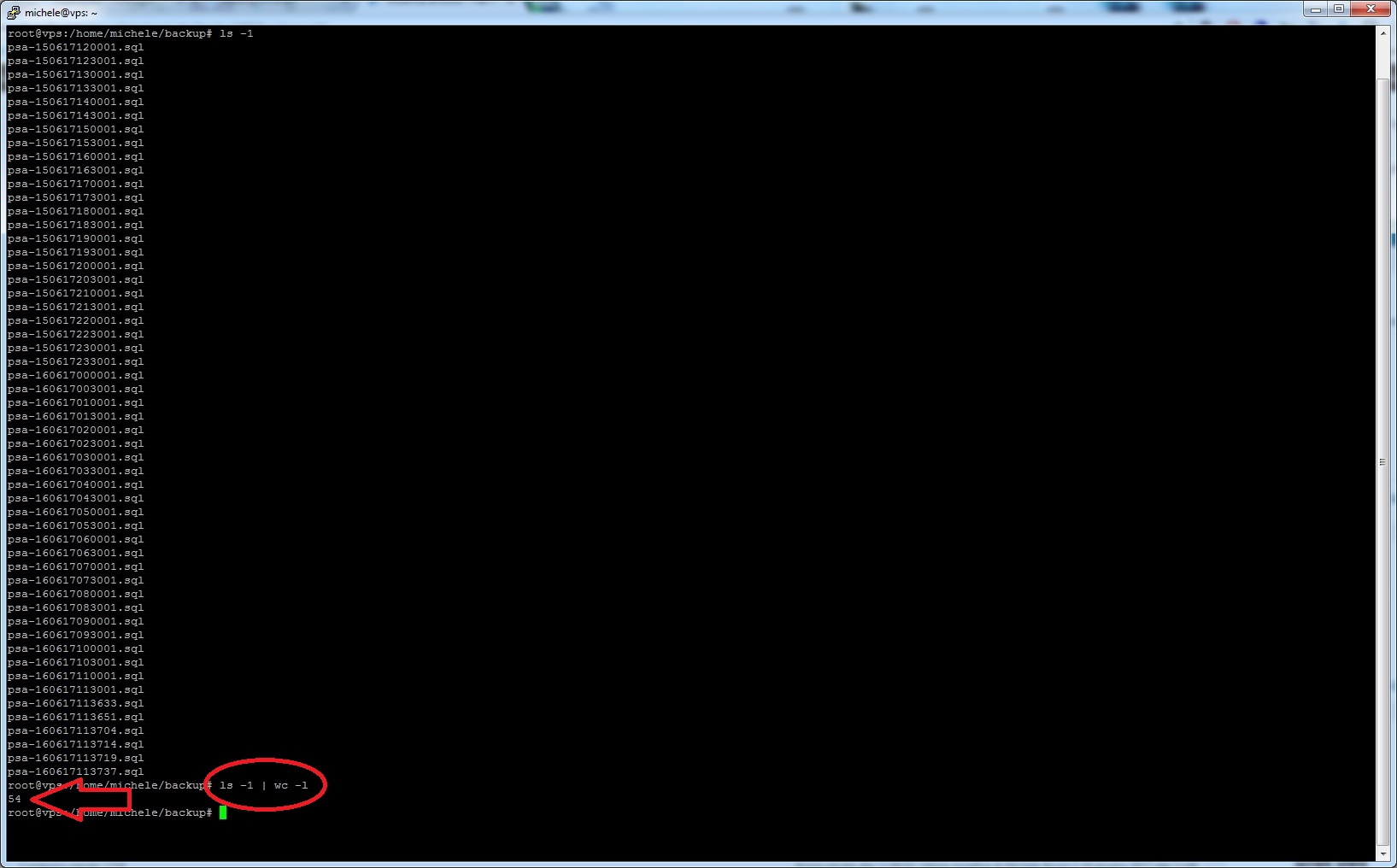
ls -1 | wc -l (Clicca per ingrandire)
Ora quindi abbiamo il conteggio diretto di ogni singola riga, così facendo possiamo capire a quanti backup siamo arrivati se facciamo eseguire lo script.
Creazione della condizione
Si parte poi con la creazione della condizione dove andremo a programmare lo script in modo tale che, dopo aver effettuato il controllo di quanti backup ha creato, vada a cancellare quello più datato se il totale dei backup creati sono più di 48, ossia uno ogni mezzora per un totale di un giorno: due volte ogni ora per 24 ore –> 24 x 2 = 48 backup.
if [ “$COUNT” -gt “48” ];
Con if (se) andiamo a “dire” allo script cosa deve fare nel caso in cui la variabile COUNT sia maggiore di 48. Per farlo usiamo l’operatore -gt (greater than) dentro alla parentesi quadra dove prima però andiamo a dichiarare quale valore deve prendere in considerazione: “$COUNT” nel nostro caso e “48”.
then
cd ${WORKDIR} && ls -1rt | head -1 | xargs rm
Successivamente con la sintassi then (poi) diciamo allo script cosa deve fare nel caso ci siano appunto più di 48 file nella directory di riferimento. Fatto questo ci spostiamo con l’operatore cd (Change Directory) nella solita directory dichiarata all’inizio del nostro articolo e abbiniamo il comando ls -1rt che ci mostrerà l’output di ogni file, uno per riga in ordine di data dove il backup più datato si troverà in alto alla lista. Successivamente in concatenazione andiamo ad abbinarci l’operatore head -1 che ci mostrerà quindi soltanto il primo file della lista che andremo poi ad eliminare con il comando xargs rm, sempre concatenandolo con il carattere pipe (|). A seguire vi mostriamo le schermate di ogni comando:
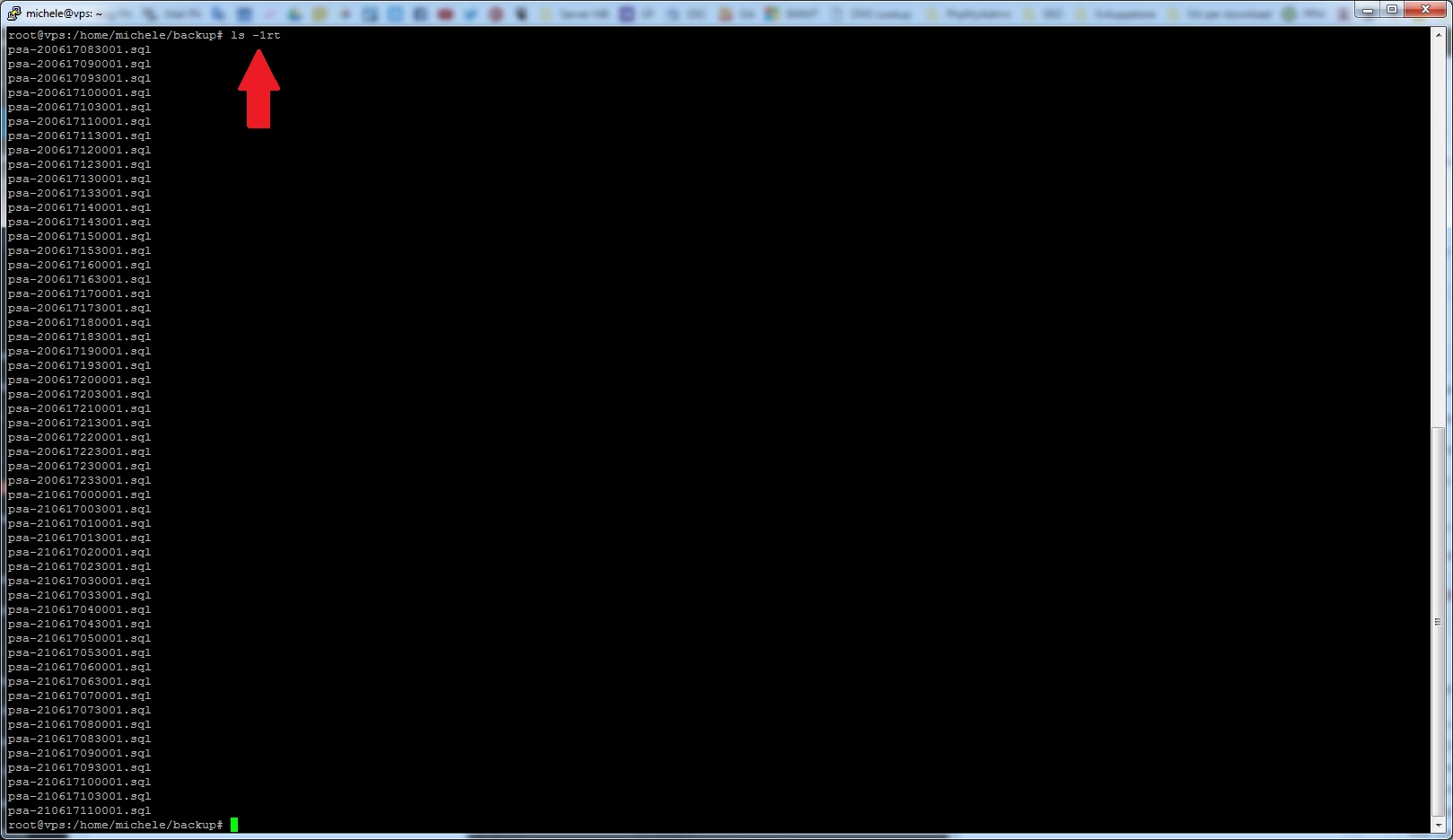
ls -1rt (clicca per ingrandire)
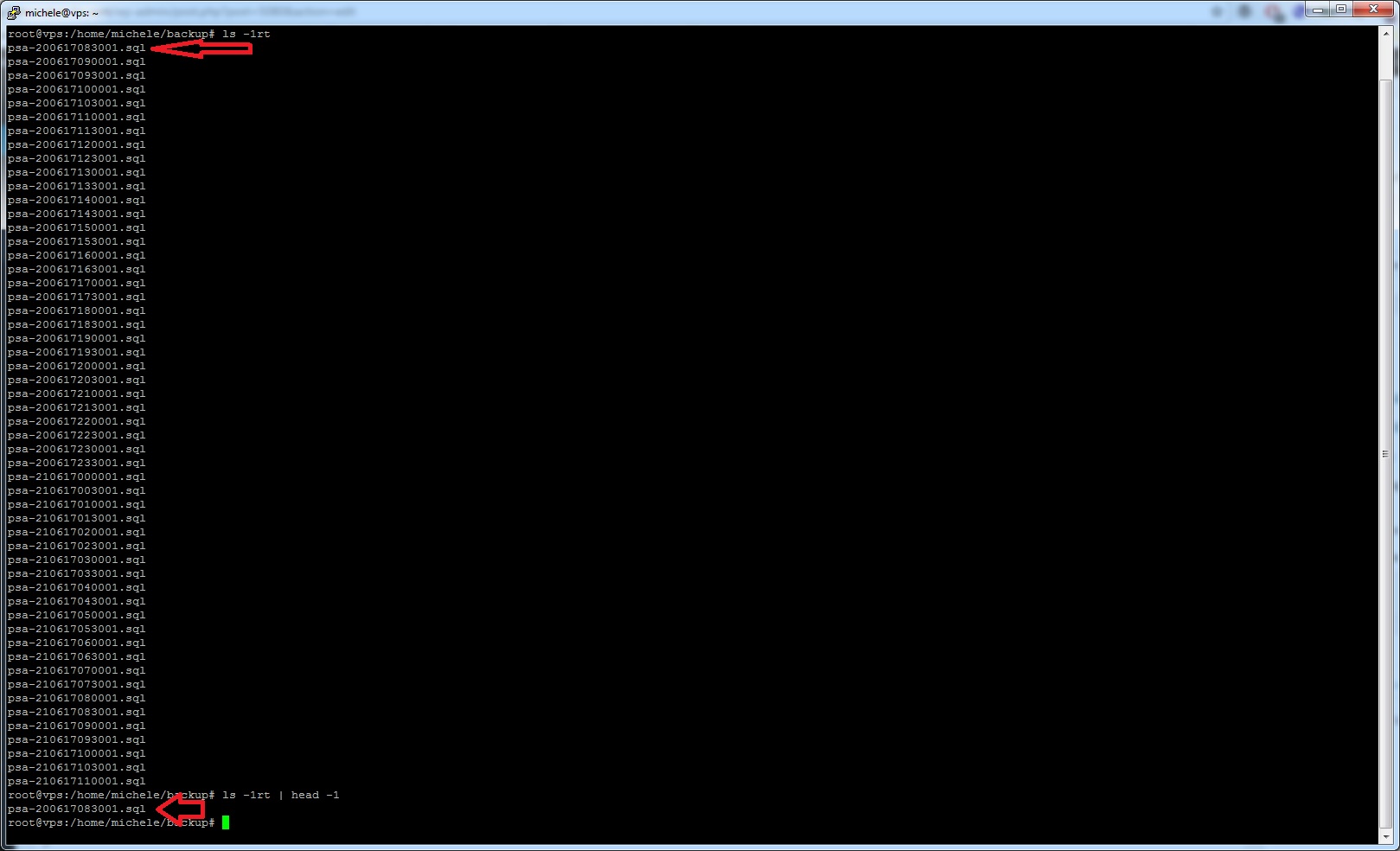
ls -1rt | head -1 (clicca per ingrandire)
Andiamo poi ad inserire la condizione else al nostro script, in quanto dobbiamo dire al programma che se la variabile count non ha raggiunto i 48 file, non deve fare nulla ed uscire dallo script, chiudendo di fatto il programma.
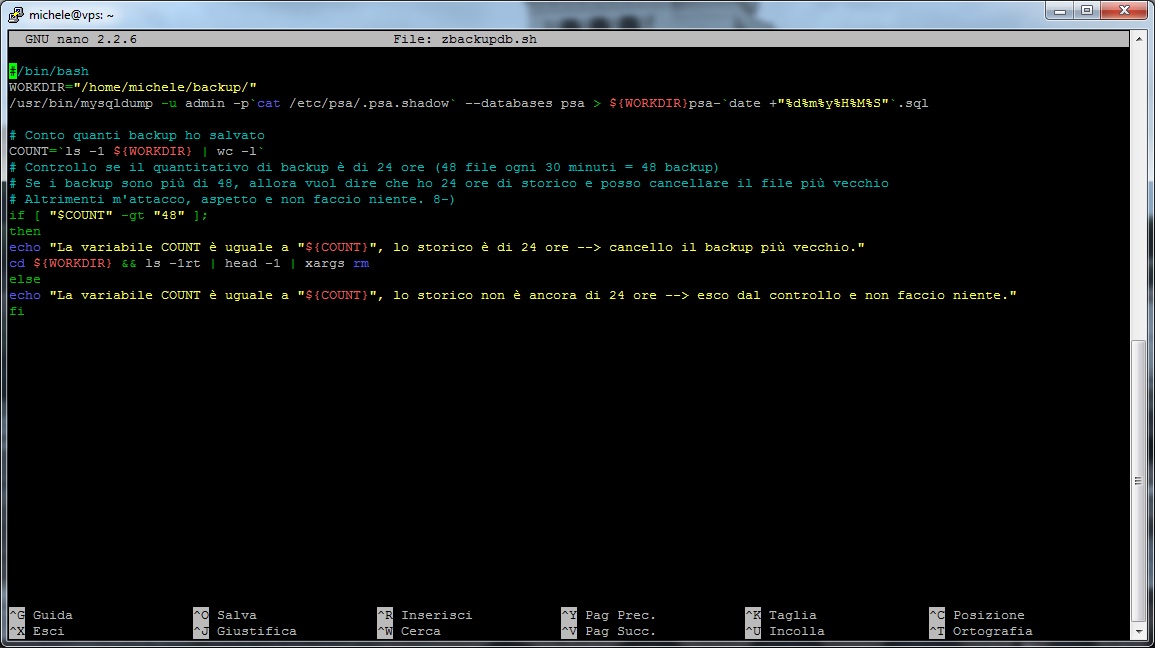
Ecco quindi lo script per intero con ogni riga commentata e l’immagine direttamente dall’editor di testo della shell:
#/bin/bash
WORKDIR=”/home/michele/backup/”
/usr/bin/mysqldump -u admin -p`cat /etc/psa/.psa.shadow` –databases psa > ${WORKDIR}psa-`date +”%d%m%y%H%M%S”`.sql# Conto quanti backup ho salvato
COUNT=`ls -1 ${WORKDIR} | wc -l`
# Controllo se il quantitativo di backup è di 24 ore (48 file ogni 30 minuti = 48 backup)
# Se i backup sono più di 48, allora vuol dire che ho 24 ore di storico e posso cancellare il file più vecchio
if [ “$COUNT” -gt “48” ];
then
echo “La variabile COUNT è uguale a “${COUNT}”, lo storico è di 24 ore –> cancello il backup più vecchio.”
cd ${WORKDIR} && ls -1rt | head -1 | xargs rm
else
echo “La variabile COUNT è uguale a “${COUNT}”, lo storico non è ancora di 24 ore –> esco dal controllo e non faccio niente.”
fi
Clicca per ingrandire
Come eseguire il backup in automatico?
Una volta creato lo script dobbiamo fare in modo che venga eseguito in automatico.
Per farlo utilizzeremo il servizio crond. Come già detto all’inizio di questo articolo, il demone crond consente di pianificare molte attività, tra cui far eseguire il nostro script appena creato. Per impostare il crontab dobbiamo entrare nell’editor che ci consente di metter mano alla sua impostazione. Per farlo basterà digitare nella shell il comando crontab -e ed inserire questa stringa:
*/30 * * * * /home/michele/nomedelloscript.sh
Ovviamente al posto del nomedelloscript.sh ci andrà il nome del nostro script.
La sintassi */30 * * * * è un’impostazione diretta del sistema crontab che farà eseguire lo script ogni mezzora per sempre, ogni giorno della settimana.
Miglioramenti
È bene sapere che ogni programma creato, nel nostro caso questo script, si può sempre migliorare e far evolvere, aggiungendoci magari delle funzioni oppure migliorarne la fruizione del codice: aggiungendo cioè dei commenti ad ogni riga di comando che abbiamo creato. In questo modo si migliorerà la vita ad un terzo programmatore che vorrà metter mano al codice dello script mentre chi lo eseguirà saprà esattamente cosa starà facendo lo script in quel momento. Potete vedere qui sopra, nell’immagine dello script intero, le parti scritte con colore blu.
Conclusione
Speriamo di avervi dato uno spunto di partenza per la creazione di script sempre più complessi e/o aiutare magari chi è alle prime armi. Il mondo della shell unix è affascinante e molto potente, soprattutto quando si devono gestire grosse quantità di dati e/o server. Non ci resta quindi che invitarvi a farci sapere nei commenti cosa pensate di questo script o per farci sapere la vostra esperienza a riguardo, magari proponendo altre soluzioni.



No Responses